步骤
- Step I: The
createElementFunction - Step II: The
renderFunction - Step III: Concurrent Mode
- Step IV: Fibers
- Step V: Render and Commit Phases
- Step VI: Reconciliation
- Step VII: Function Components
- Step VIII: Hooks
step0.Review
对象表示元素
jsx→valid JS
JSX通过像Babel这样的构建工具转换为JS。
转换通常很简单:将标签中的代码替换为对 createElement 的调用,将标签名称、props 和子项作为参数传递。
const element = <h1 title="foo">Hello</h1>
--------等价--------------
const element = {
type: "h1",
props: {
title: "foo",
children: "Hello",
},
}
step1.createElement函数
step2.render函数
step3.并行模型
step4.Fiber
Fiber
在React 16版本之前,React 使用的是名为Stack Reconciler的旧调和算法。Stack Reconciler 的核心是递归遍历组件树,把数据保存在递归调用栈中。它使用的深层递归遍历方法。
但是使用递归遍历组件树时,会导致一些问题:
- 阻塞主线程:JavaScript 是单线程的。如果组件树很大或者更新很频繁,递归调用可能会导致 UI 变得不流畅,影响用户体验。
- 没有优先级调度:
Stack Reconciler无法对不同的更新任务进行优先级调度,所有的更新任务都会被视为相同的优先级。这意味着对于高优先级的任务(如动画或用户交互),React 无法优先处理,从而可能导致性能下降。
为了解决这些问题,React 引入了 Fiber Reconciler。Fiber Reconciler 使用了一种名为 "Fiber" 的新数据结构来表示组件树。
特点:
- 介于
ReactElement与真实UI节点之间; - 能够表达节点之间的关系;
- 方便拓展,不仅作为数据存储单元,也能作为工作单元;
FiberNode 是虚拟DOM在React中的实现
FiberNode Tree的数据结构如图所示:
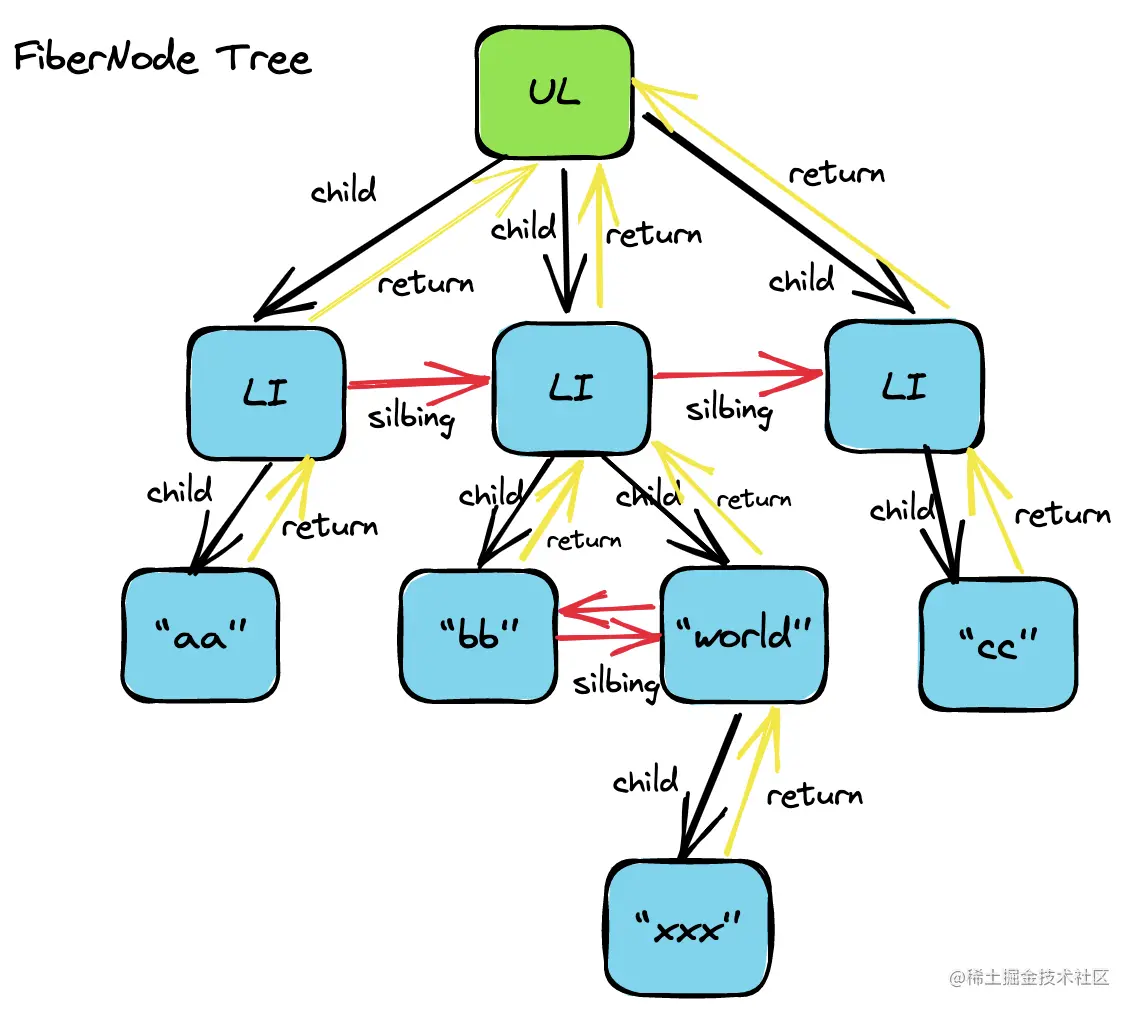
FiberNode 上有很多属性,包括和自身相关的属性 ref,节点之间的关系 return、silbing还有工作单元上的属性,比如 pendingProps等等
// 主要的,不包含全部
type FiberNode = {
// 作为静态属性
tag: WorkTag, // 标识FunctionComponent/HostComponent/HostText等,通过比较两个节点的 WorkTag 属性来判断它们是否是同一类型的节点,而不需要通过字符串比较等方式,这样可以提高比较的效率,也可以减少出错的可能性
key: null | string,
type: any, // 同ReactElement fiber对应的DOM元素的标签类型,div、p...
elementType: any, // 大部分情况同type,某些情况不同,比如FunctionComponent使用React.memo包裹
stateNode: any, // 存dom节点
index: number,
ref: any,
refCleanup: null | (() => void),
// 用于组成Fiber树
return: Fiber | null, // 父
child: Fiber | null, // 子
sibling: Fiber | null, // 右边第一个兄弟
// 作为工作单元,保存本次更新造成的状态改变相关信息
// 要更新的新props
pendingProps: any,
// 计算后的props
memoizedProps: any,
// 更新队列
updateQueue: mixed,
// 计算出的新状态
memoizedState: any,
// 保存context、事件相关内容
dependencies: Dependencies | null,
mode: TypeOfMode,
// 副作用
flags: Flags,
// 子树的所有节点的flags
subtreeFlags: Flags,
// 要删除的子fiberNode
deletions: Array<Fiber> | null,
nextEffect: Fiber | null,
firstEffect: Fiber | null,
lastEffect: Fiber | null,
// 用于调度 优先级
lanes: Lanes,
childLanes: Lanes,
// 指向对应的workInProgress FiberNode或者current FiberNode
alternate: Fiber | null,
Fiber树
function App() {
return (
<Header>
<img />
<span>hello! react18</span>
</Header>
);
}
function Header({ children }) {
return <header>{children}</header>;
}
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(<App />);
这段JSX代码运行后会生成一个如下所示的 Fiber树,其中有两个特殊的节点:
fiberRootNode:整个 Fiber树 的根结点,此节点的current属性指向的就是current Fiber树,对应的还有workInprogress Fiber树。-
hostRootFiber:挂载 React 应用的 dom 对应的fiberNode。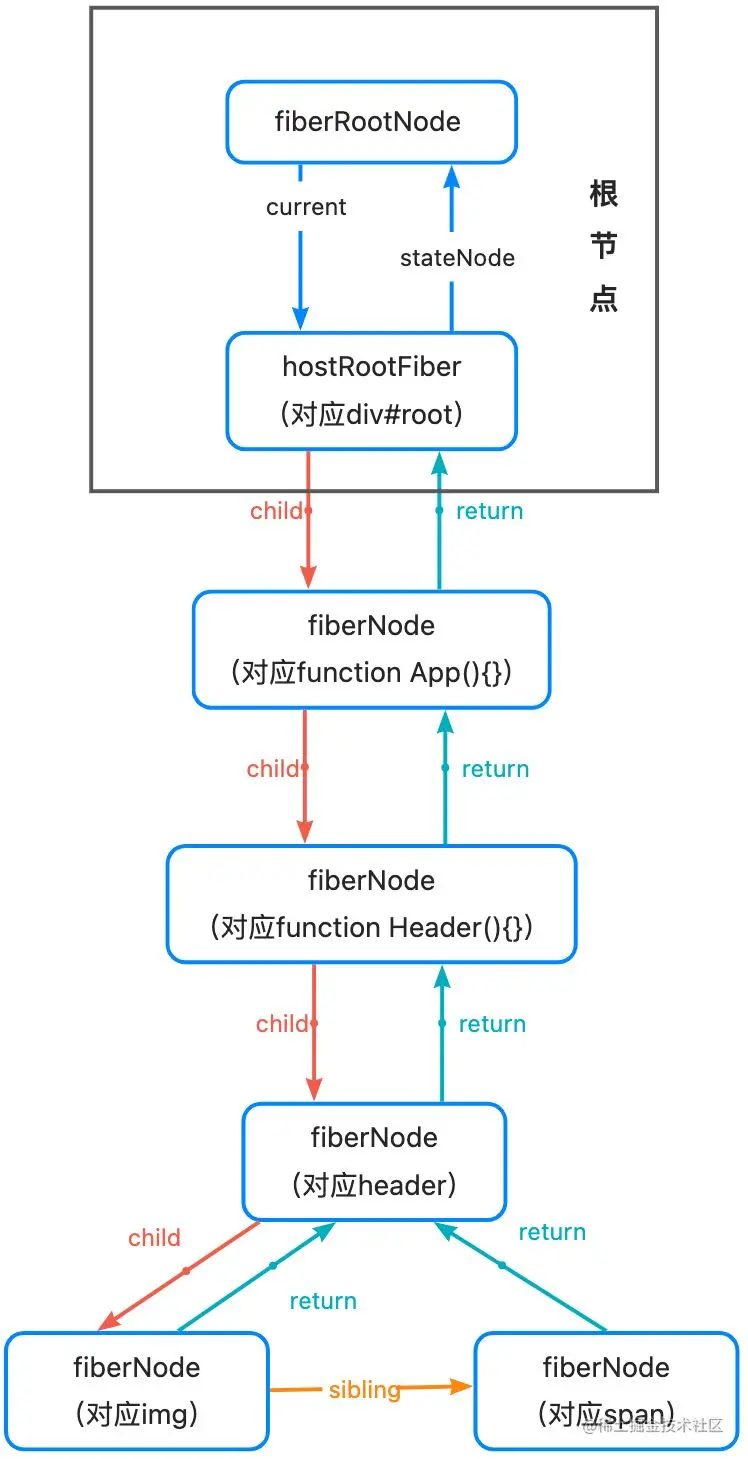 有一点需要说明的是,span下面的
有一点需要说明的是,span下面的TextNode没有对应的fiberNode,这是 React 的一条优化路径,只有唯一文本节点的fiberNode就不会再生成子fiberNode了。
❓:我曾有一个疑问,在上述这段JSX结构中,Header 组件下还有img和span节点,函数内部又有header节点,那么 Header 的fiberNode.child指向的是img的fiberNode呢还是内部的header的呢?
✅:指向的是header的,img和span会存到Header组件的props.children中,如果我渲染了children,那么img和span也会生成对应的fiberNode,并且在 Fiber树中的节点位置会是渲染的位置,并不是定义时的位置;如果不渲染,那也就不会生成与之对应的fiberNode。这也说明了FiberNode是Fiber架构运行时动态的工作单元,并不像ReactElement一样只是静态结构。
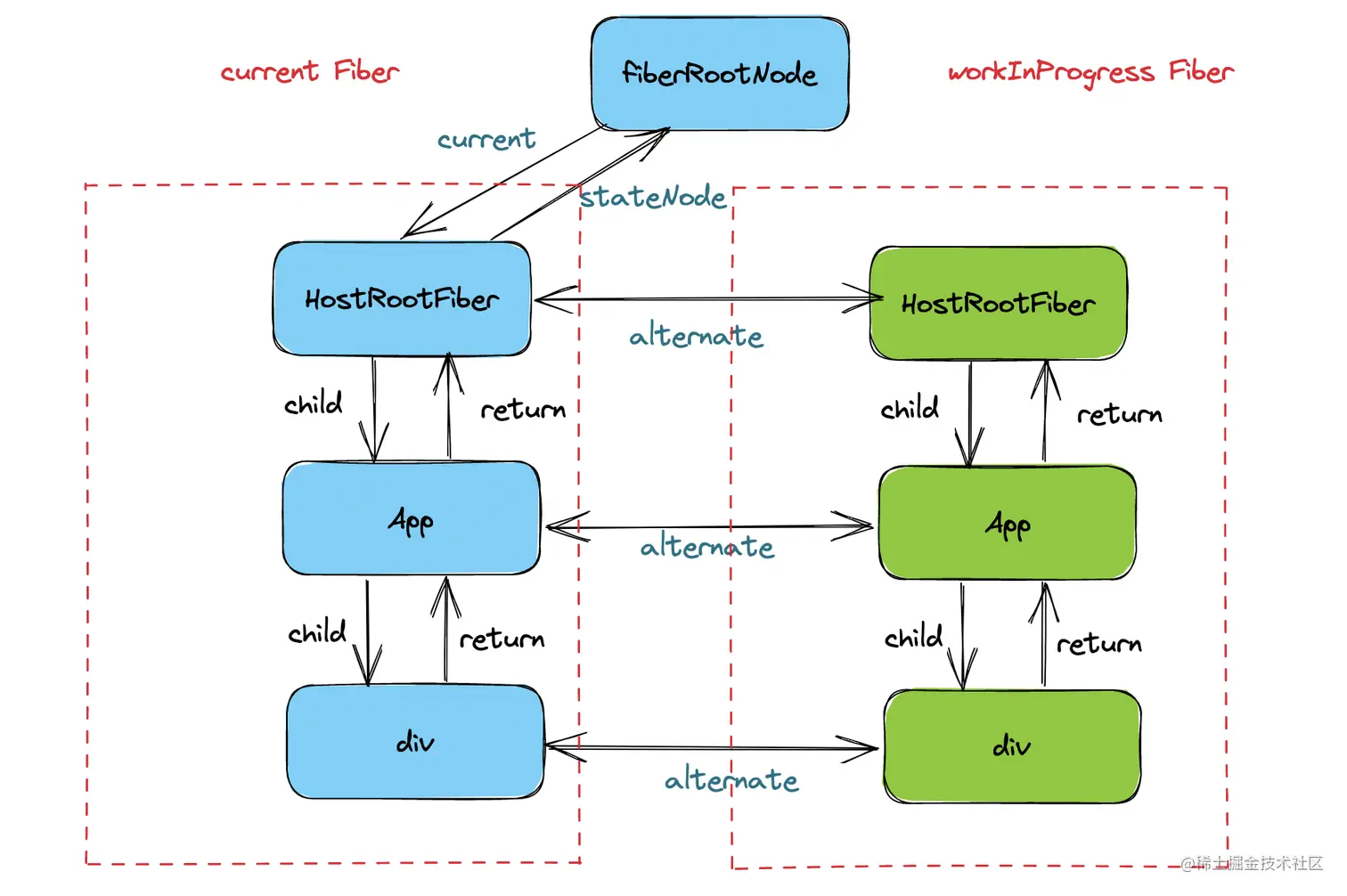
两颗Fiber树(双缓存)
双缓存技术是一种计算机图形学中用于减少屏幕闪烁和提高渲染性能的技术
对于React来说,寻找state和UI对应关系的大致流程是从根节点开始遍历Fiber树,一路上标记发生改变的fiberNode,最终再将改变映射到真实UI上。
为了不影响到当前显示使用的Fiber树(名为current Fiber树),在映射到真实UI之前React的活动都是在内存中进行的,内存中也存在一个Fiber树,名为workInProgress Fiber树,两颗Fiber树之间互相以alternate属性连接。
每次状态更新都会产生新的workInProgress Fiber树,通过current与workInProgress的替换,完成DOM更新,这就是React中用的双缓存树切换规则
工作完成后根节点的current属性就会指向workInProgress Fiber树,workInProgress Fiber树和current Fiber树位置就互换了,这种技术也被称为双缓存,简而言之就是后台工作,完成以后前台后台位置互换。
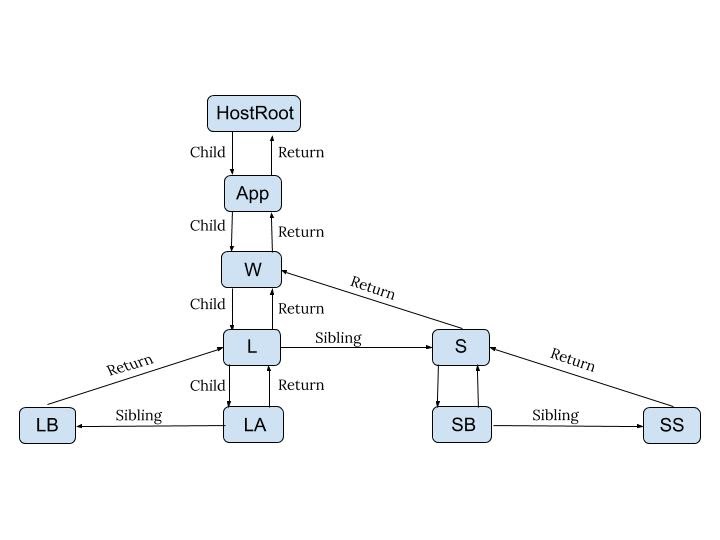
工作流程
在初始化挂载(mount)时,React会先创建根节点fiberRootNode,然后从根节点开始创建workInProgressFiber树;在更新发生(update)时,React会从发生动作的fiberNode开始向上找到根节点(fiberRootNode.stateNode即hostRootFiber),然后从根节点开始生成新的wip Fiber树,当然此时的生成不是从0开始创建,会根据一些条件复用或删除已存在的wip Fiber树中的某些节点。 在wip Fiber树构建过程中会根据改变打上对应的标记,比如插入或删除标记。构建完成后会遍历wip,根据不同的标记进行操作,最终将对应的UI渲染到页面上。
这就是大致的工作流程,这个过程中主要有两个大的阶段:
-
render阶段:从根节点开始创建wip Fiber树,计算出每个fiberNode发生的更新,标记在flags和subtreeFlags上 -
commit阶段:把每个fiberNode的改变提交在宿主环境中,比如在浏览器上就是更新dom
React Fiber 实现这种工作进度保存的原理是通过将任务拆分成更小的单元,然后使用链表数据结构来管理它们的顺序。每个任务都有一个指向其下一个任务的指针,并且每当 React 执行一个任务时,它会检查是否需要中断当前任务并将控制权交回给浏览器。如果是,则React 使用 save/restore 机制将当前任务的状态保存到堆栈中,并从链表的下一个任务开始执行,直到所有任务都被处理完毕.
step5.分离Render和Commit阶段
step6.Reconciliation (diffing算法)
reconcileChildren 优化newFiber的构建过程
调用栈
render(),初始化rootFiber,并设为nextUnitOfWork
workLoop -> .performUnitOfWork
performUnitOfWork -> reconcileChildren
reconcileChildren ,同时遍历 olfFiber和 elements,开始diffin
- type相同:直接继承dom,添加新属性 UPDATE
- 类型不同且有新元素:新建一个Fiber PLACEMENT
- 类型不同,有旧Fiber:删除这个旧Fiber,DELETION
创建好新的Fiber,构建 Fiber Tree
出reconcileChildren
performUnitOfWork ,返回下一个fiber
循环,直到Fiber Tree 形成
进入commitRoot
先处理deletions,从DOM树中移除
然后处理子节点:
PLACEMENT : 进入append
UPDATE : 进入updateDOM
updateDOM干啥呢:
- 删除已丢弃的props
- 添加新增/修改变化的属性
- 删除丢弃/变化的事件处理函数
- 添加新的事件处理函数
最后把currentRoot赋值为当前的渲染(wipRoot),初始化wipRoot为null,等待下一次渲染
step7.函数式组件
函数式组件没有自己的DOM
追加和删除都要向上or向下找最近的DOM节点
函数时组件的children试运行出来的,不是props里拿出来